반응형
재미를 목적으로 만든 카카오톡 대화 분석기입니다.
우리 단톡방은 언제 말이 많았고, 누가 어떤 말을 많이 사용하는지 알 수 있었네요.
(개인신상과 관련된 부분은 가렸습니다.)
파이썬+주피터를 사용했습니다.







코드
카카오톡의 대화내용 내보내기 기능을 이용하여 추출한 csv파일을 이용했습니다.
#!/usr/bin/env python
# coding: utf-8
# # 카카오톡 대화 분석기
#
# In[ ]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
get_ipython().run_line_magic('matplotlib', 'inline')
import locale
locale.setlocale(locale.LC_ALL, 'ko_KR.UTF-8')
# In[ ]:
df=pd.read_csv("talk.csv")
# In[ ]:
df.head()
# ## 전처리
# - Date 변수 나누기
# - 시스템 메시지 제거
# - 초대했습니다.
# - 나갔습니다.
# - 결측값 처리
# ### Date 변수 나누기
#
# In[ ]:
df["Date"]=df["Date"].astype("datetime64")
df["year"]=df["Date"].dt.year
df["month"]=df["Date"].dt.month
df["day"]=df["Date"].dt.day
df["hour"]=df["Date"].dt.hour
df['weekday']=df["Date"].dt.strftime("%A")
# ### 시스템 메시지 제거
# In[ ]:
df=df[~df["Message"].str.contains("invited")]
df=df[~df["Message"].str.contains("나갔습니다.")]
# ### 결측값 제거
# In[ ]:
df.isnull().sum()
# In[ ]:
df["User"]=df["User"].fillna("(알 수 없음)")
# ## 분석
# 기간 : 2014-02-13 ~ 2019-08-23(약 6년)
# 메시지 개수 : 213,047건
# - 날짜
# - 연도별 메시지 개수
# - 월별 메시지 개수
# - 요일별 메시지 개수
# - 시간별 메시지 개수
# - 내용
# - 보낸 사람별 메시지 개수
# - 이모티콘 사용 순위
# - 사진 보내기 순위
# - 욕설 순위
# - ㅅㅂ
# - ㅂㅅ
# - ㅁㅊ
# - 감탄 순위
# - 우와
# - 웃음 순위
# - ㅋ
# - 눈물 순위
# - ㅠ
# - 강조 순위
# - !
# - 의문 순위
# - ?
#
# - ㅋㅋ이 가장 많은 대화(예정)
#
# ### 날짜
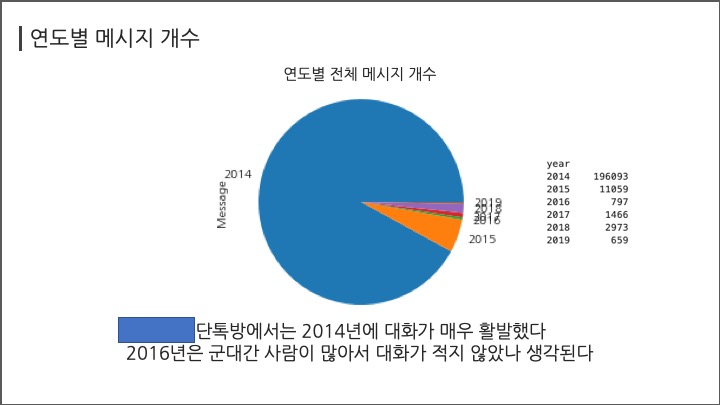
# #### 연도별 메시지 개수
# In[ ]:
df.groupby("year")["Message"].count()
# In[ ]:
df.groupby("year")["Message"].count().plot(kind="pie")
# #### 월별 메시지 개수
# In[ ]:
df.groupby("month")["Message"].count()
# In[ ]:
df[df["year"]==2014].groupby("month")["Message"].count().plot(kind="pie");
# In[ ]:
df[df["year"]==2019].groupby("month")["Message"].count().plot(kind="pie");
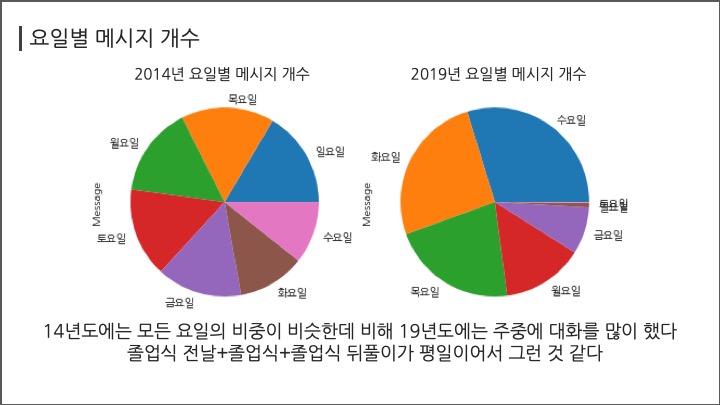
# #### 요일별 메시지 개수
# In[ ]:
df.groupby("weekday")["Message"].count().sort_values(ascending=False)
# In[ ]:
df[df["year"]==2014].groupby("weekday")["Message"].count().sort_values(ascending=False).plot("pie");
# In[ ]:
df[df["year"]==2019].groupby("weekday")["Message"].count().sort_values(ascending=False).plot("pie");
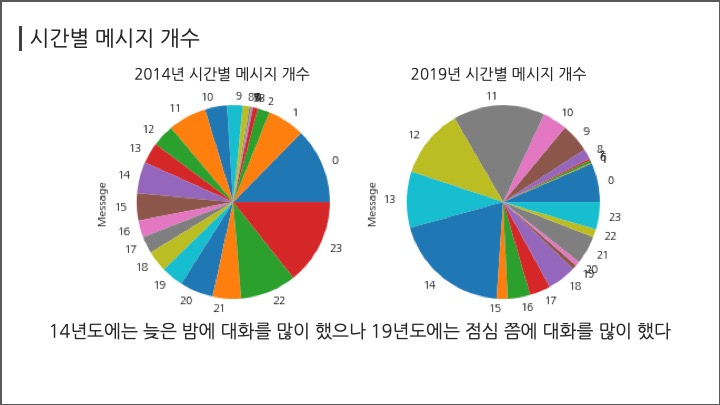
# #### 시간별 메시지 개수
# In[ ]:
df.groupby("hour")["Message"].count()
# In[ ]:
df[df["year"]==2014].groupby("hour")["Message"].count().plot("pie");
# In[ ]:
df[df["year"]==2019].groupby("hour")["Message"].count().plot("pie");
# ### 내용
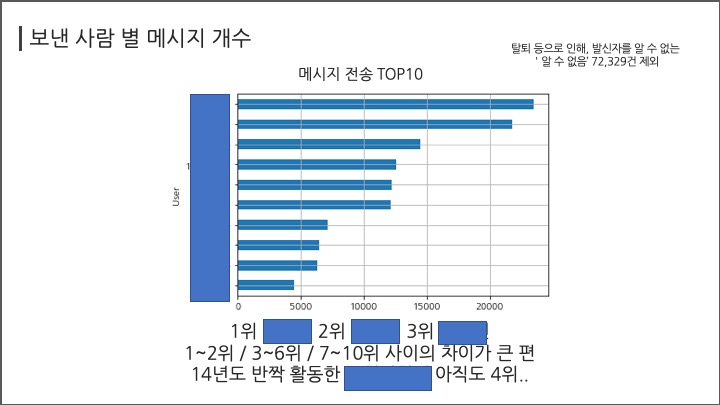
# #### 보낸사람별 메시지 개수
# In[ ]:
df.groupby("User")["Message"].count().sort_values(ascending=False)
# In[ ]:
df.groupby("User")["Message"].count().sort_values(ascending=True)[-11:].plot(kind="barh",grid=True);
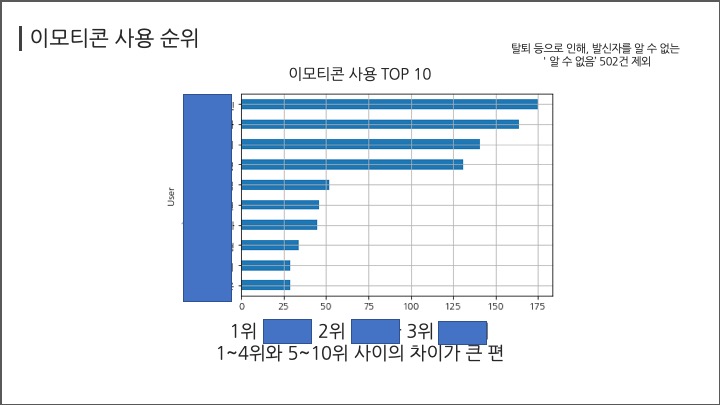
# #### 이모티콘 사용 순위
# In[ ]:
df[df["Message"]=="이모티콘"].groupby("User")["Message"].count().sort_values(ascending=False)[:10]
# In[ ]:
df[df["Message"]=="이모티콘"].groupby("User")["Message"].count().sort_values(ascending=True)[-11:].plot(kind="barh",grid=True);
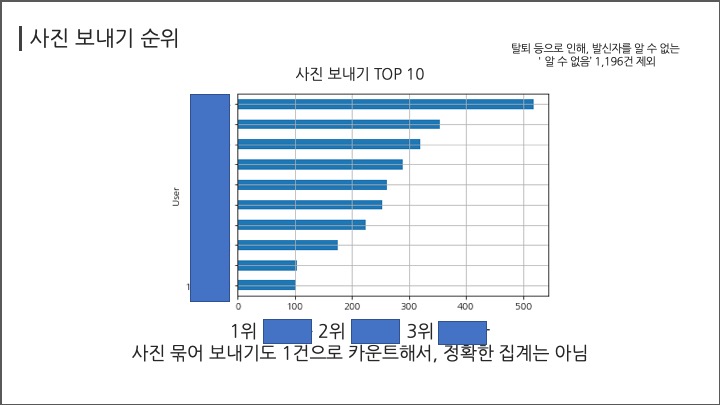
# #### 사진 보내기 순위
# In[ ]:
df[df["Message"]=="사진"].groupby("User")["Message"].count().sort_values(ascending=False)[:10]
# In[ ]:
df[df["Message"]=="사진"].groupby("User")["Message"].count().sort_values(ascending=True)[-11:].plot(kind="barh",grid=True);
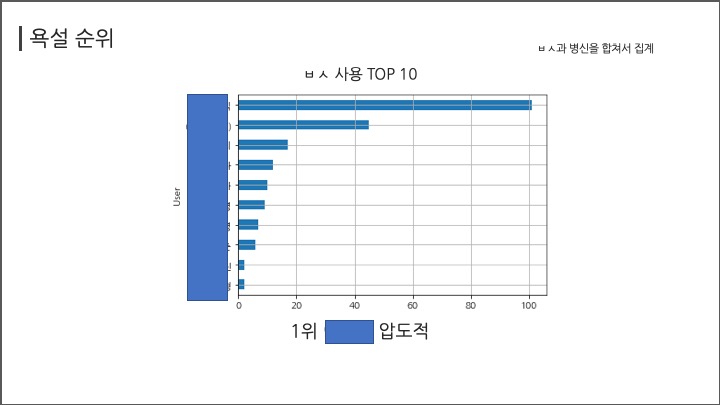
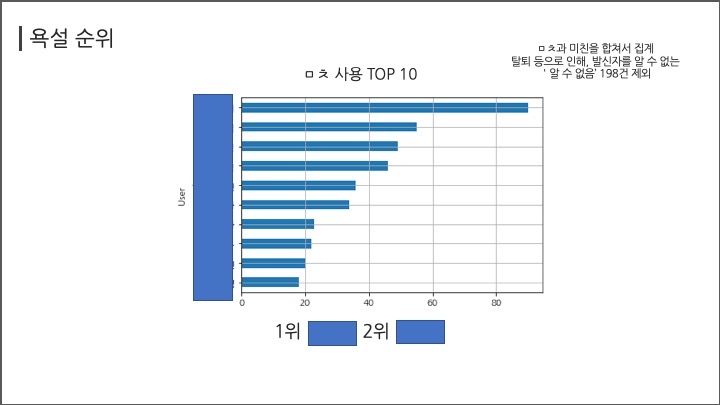
# #### 욕설 순위
# ##### ㅅㅂ
# In[ ]:
df[(df["Message"].str.contains("ㅅㅂ"))|(df["Message"].str.contains("시발")) ].groupby("User")["Message"].count().sort_values(ascending=False)[:5]
# In[ ]:
df[(df["Message"].str.contains("ㅅㅂ"))|(df["Message"].str.contains("시발")) ].groupby("User")["Message"].count().sort_values(ascending=True)[-10:].plot(kind="barh",grid=True);
# ##### ㅂㅅ
# In[ ]:
df[(df["Message"].str.contains("ㅂㅅ"))|(df["Message"].str.contains("병신"))].groupby("User")["Message"].count().sort_values(ascending=False)[:5]
# In[ ]:
df[(df["Message"].str.contains("ㅂㅅ"))|(df["Message"].str.contains("병신")) ].groupby("User")["Message"].count().sort_values(ascending=True)[-10:].plot(kind="barh",grid=True);
# ##### ㅁㅊ
# In[ ]:
df[(df["Message"].str.contains("ㅁㅊ"))|(df["Message"].str.contains("미친"))].groupby("User")["Message"].count().sort_values(ascending=False)[:5]
# In[ ]:
df[(df["Message"].str.contains("ㅁㅊ"))|(df["Message"].str.contains("미친")) ].groupby("User")["Message"].count().sort_values(ascending=True)[-11:].plot(kind="barh",grid=True);
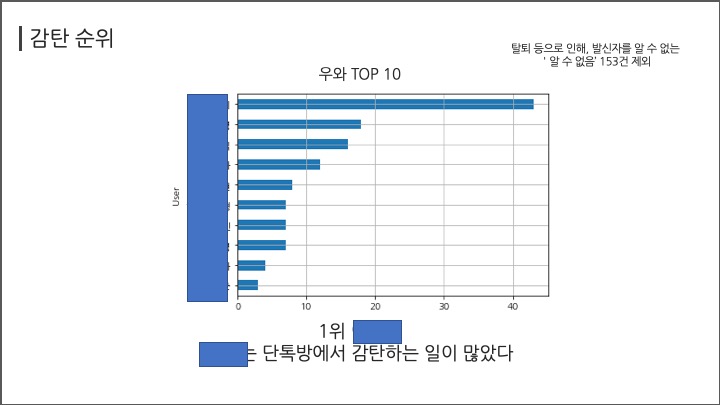
# #### 감탄 순위
# ##### 우와
# In[ ]:
df[df["Message"].str.contains("우와")].groupby("User")["Message"].count().sort_values(ascending=False)[:5]
# In[ ]:
df[df["Message"].str.contains("우와")].groupby("User")["Message"].count().sort_values(ascending=True)[-11:-1].plot(kind="barh",grid=True);
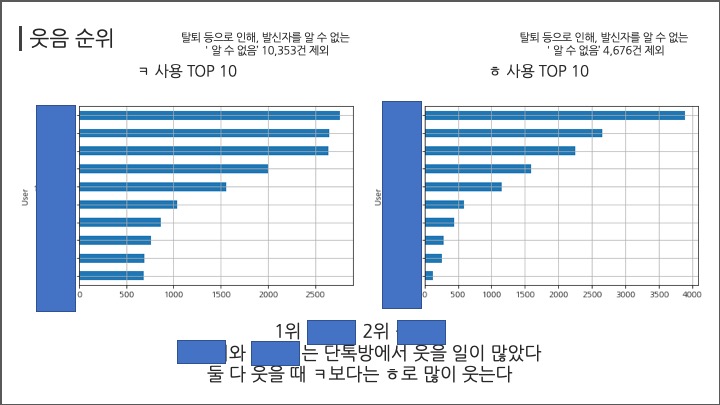
# #### 웃음 순위
# ##### ㅋ
# In[ ]:
df[df["Message"].str.contains("ㅋ")].groupby("User")["Message"].count().sort_values(ascending=False)[:10]
# In[ ]:
df[df["Message"].str.contains("ㅋ")].groupby("User")["Message"].count().sort_values(ascending=True)[-11:-1].plot(kind="barh",grid=True);
# ##### ㅎ
# In[ ]:
df[df["Message"].str.contains("ㅎ")].groupby("User")["Message"].count().sort_values(ascending=False)[:10]
# In[ ]:
df[df["Message"].str.contains("ㅎ")].groupby("User")["Message"].count().sort_values(ascending=True)[-11:-1].plot(kind="barh",grid=True);
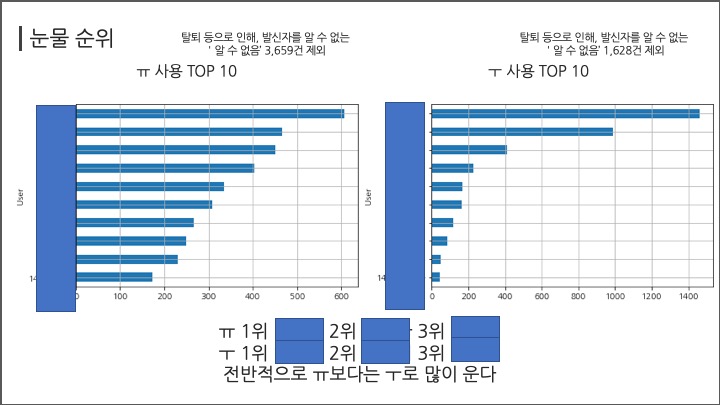
# #### 눈물 순위
# ##### ㅠ
# In[ ]:
df[df["Message"].str.contains("ㅠ")].groupby("User")["Message"].count().sort_values(ascending=False)[:10]
# In[ ]:
df[df["Message"].str.contains("ㅠ")].groupby("User")["Message"].count().sort_values(ascending=True)[-11:-1].plot(kind="barh",grid=True);
# ##### ㅜ
# In[ ]:
df[df["Message"].str.contains("ㅜ")].groupby("User")["Message"].count().sort_values(ascending=False)[:10]
# In[ ]:
df[df["Message"].str.contains("ㅜ")].groupby("User")["Message"].count().sort_values(ascending=True)[-11:-1].plot(kind="barh",grid=True);
# #### 강조 순위
# ##### !
# In[ ]:
df[df["Message"].str.contains("!")].groupby("User")["Message"].count().sort_values(ascending=False)[:10]
# In[ ]:
df[df["Message"].str.contains("!")].groupby("User")["Message"].count().sort_values(ascending=True)[-11:-1].plot(kind="barh",grid=True);
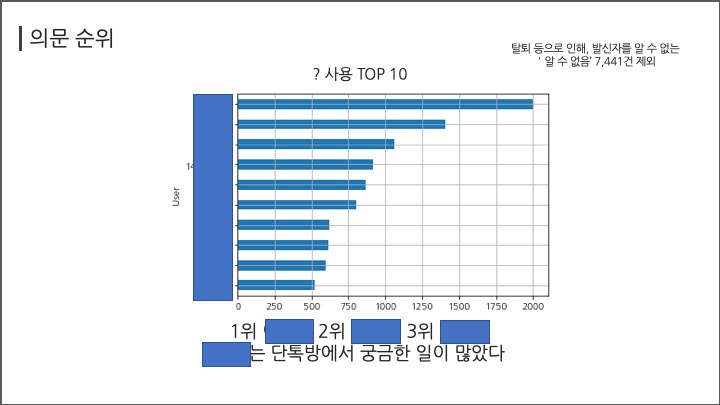
# #### 의문 순위
# ##### ?
# In[ ]:
df[df["Message"].str.contains("\?")].groupby("User")["Message"].count().sort_values(ascending=False)[:10]
# In[ ]:
df[df["Message"].str.contains("\?")].groupby("User")["Message"].count().sort_values(ascending=True)[-11:-1].plot(kind="barh",grid=True);
# ### 번외
# #### 사과 순위
# In[ ]:
df[df["Message"].str.contains("미안")].groupby("User")["Message"].count().sort_values(ascending=True)[-11:].plot(kind="barh",grid=True);
# #### 존나 순위
# In[ ]:
df[(df["Message"].str.contains("ㅈㄴ"))|(df["Message"].str.contains("존나")) ].groupby("User")["Message"].count().sort_values(ascending=True)[-11:].plot(kind="barh",grid=True);
# #### 감사 순위
# In[ ]:
df[(df["Message"].str.contains("ㄱㅅ"))|(df["Message"].str.contains("감사"))|(df["Message"].str.contains("고마워"))|(df["Message"].str.contains("고맙")) ].groupby("User")["Message"].count().sort_values(ascending=True)[-11:].plot(kind="barh",grid=True);
# #### 굿 순위
# In[ ]:
df[df["Message"].str.contains("굿")].groupby("User")["Message"].count().sort_values(ascending=True)[-11:].plot(kind="barh",grid=True);
자유롭게 사용하시고
도움이 되었다면 공감이나 댓글 부탁드립니다!
반응형
'데이터 분석' 카테고리의 다른 글
| Matrix Factorization 알고리즘을 사용한 상품 추천 (0) | 2021.01.13 |
|---|---|
| [kaggle]유튜브 인기 동영상 데이터 분석(파이썬) (2) | 2020.02.26 |
| 알바몬 분석: 알바몬 경기의 공고수는 몇개나 될까 (0) | 2019.08.18 |
| 공공데이터 활용 - 교통사고 통계 리포트 (0) | 2019.07.18 |